
This post is for laughs, a piece of a sit-down comedy. Admittedly, it’s making fun of some things I have written in the past. I wrote it a while ago, on a plane from law&tech conference to another. I wanted to pair it with a serious part: a reflection on what is it that we do, what we should do, what’s the point etc. Somehow, however, I never managed. On the same time, I keep showing this to people on my phone during conferences and they laugh. And laughing is good for you! Hence, I thought I’ll share it, so you can smirk, and maybe someone wiser than me will come up with a serious comment on what is behind this. Ready? Let’s go!
How to write a generic law and technology paper
So, you have given a lecture using the speech generator and now they asked you to write a paper. Worried? No need! The instruction below will help you develop a state-of-the-art contribution in ten steps.
- Start with a story. Write a couple-paragraph-long horrifying/utopian story about how a technology you are talking about will soon completely change the world, and undermine one of the legally protected values: property, freedom, equality, transparency, non-discrimination, safety, privacy, anything. Don’t explain what you mean by “technology”, but be sure to mention that it is “disruptive”. If you can find some data (numbers are always impressive), cite it; even better if you can find someone (anyone, really) who has published a prediction that in 5 years everyone will be using this. You can also start with some inspirational quote.
- Name the technology: robotics, AI, internet of things, big data, blockchain, algorithms, platforms, sharing economy, wearables, again anything. Say that there is no agreed upon definition of it, then define it anyhow, give a few more examples. If you write about IoT, make sure your example is a fridge ordering milk when you are out of it.
- Indicate what are some laws that could apply to this technology – cite some statues, some cases, no need to be comprehensive – just have one that would be unclear in application. Alternatively, take some established concept: liability, personality, accountability etc. and show how this new technology makes its application complicated. This will make everyone think that this is a legal paper. Lawyers usually don’t know much about tech, and non-lawyers seldom read cases – this will make you seem like an expert in the other area than the reader comes from.
- State that we need to regulate, in a way that will “mitigate the risks, without impeding the benefits”.
- Say that obviously there are some benefits, and list them: pay special attention to how this could be used in education, or medicine, or for any type of empowerment (no need to define).
- Say that, however, there are of course also some risks/challenges, and list them. No need to indicate what the criteria of distinction was, also don’t worry about explaining your normative theory (just say “criminal law”, or “consumer law”, or “privacy” etc.). Just list the problems.
- Now it’s time to solve a problem: throw around one/three/five ideas on what to do. If you are creative here that’s ok, but you can also go for some safe bets: create a new administrative agency (“FDA for algorithms/robots/databases etc.), incentivize self-regulation and creation of codes of conduct, and education – education is the most important.
- (Optional: write a couple of paras explaining why your solutions are better than what other people proposed, or what is already in place. This takes more time, because you actually need to read something. But will make you look like an expert. If you treat people nicely, you might even become a member of a #citationCartel).
- Mention blockchain. You can just literally put the word “blockchain” in a random place somewhere in the solution section.
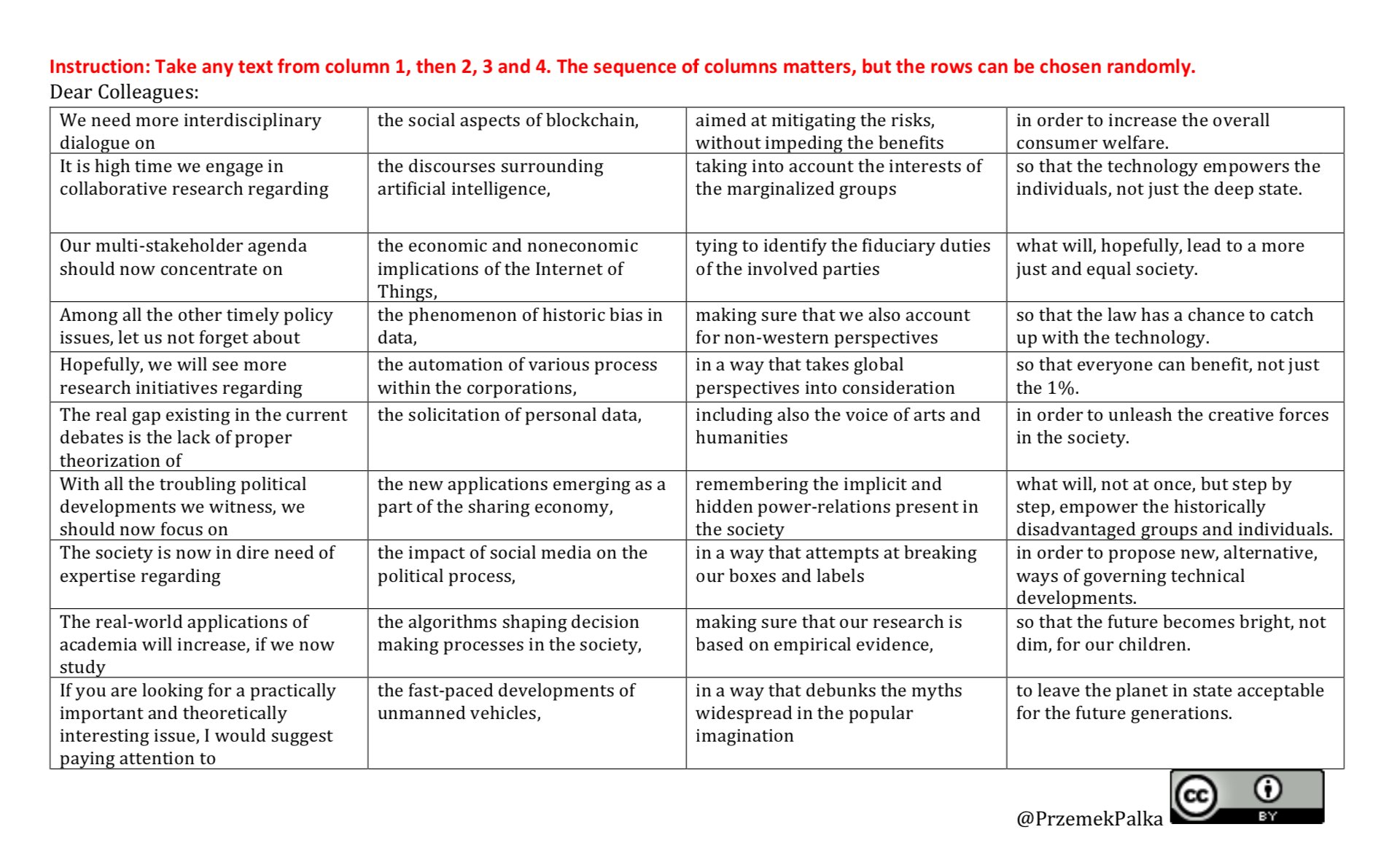
- Finish by saying that the issue is obviously complex, so more interdisciplinary perspectives are needed, and that you know you might be wrong, but your first ambition was to draw attention to the problem and start a discussion.
There you go! The paper is essentially ready. You just became an expert in something new, congratulations!!!

{kind=link}